Building a model to predict the sex of three species of penguins of Palmer Penguins data.
Tip
This is my first Machine Learning project and I am still learning as of this date. This work is inspired by Julia Silge and you can find the original work by her in her blog and would like to thank her for the teachings in Julia Silge -Youtube channel
1 Exploring the data
library(tidyverse)library(palmerpenguins)penguins
# A tibble: 344 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
7 Adelie Torgersen 38.9 17.8 181 3625
8 Adelie Torgersen 39.2 19.6 195 4675
9 Adelie Torgersen 34.1 18.1 193 3475
10 Adelie Torgersen 42 20.2 190 4250
# ℹ 334 more rows
# ℹ 2 more variables: sex <fct>, year <int>
The data set is from palmerpenguins library which contains observations of Antarctic pebguins from the Palmer Archipelago. You can read more about how this dataset came to be in this post on the RStudio Education blog. Our modeling goal here is to predict the sex of the penguins using a classification model, based on other observations in the dataset.
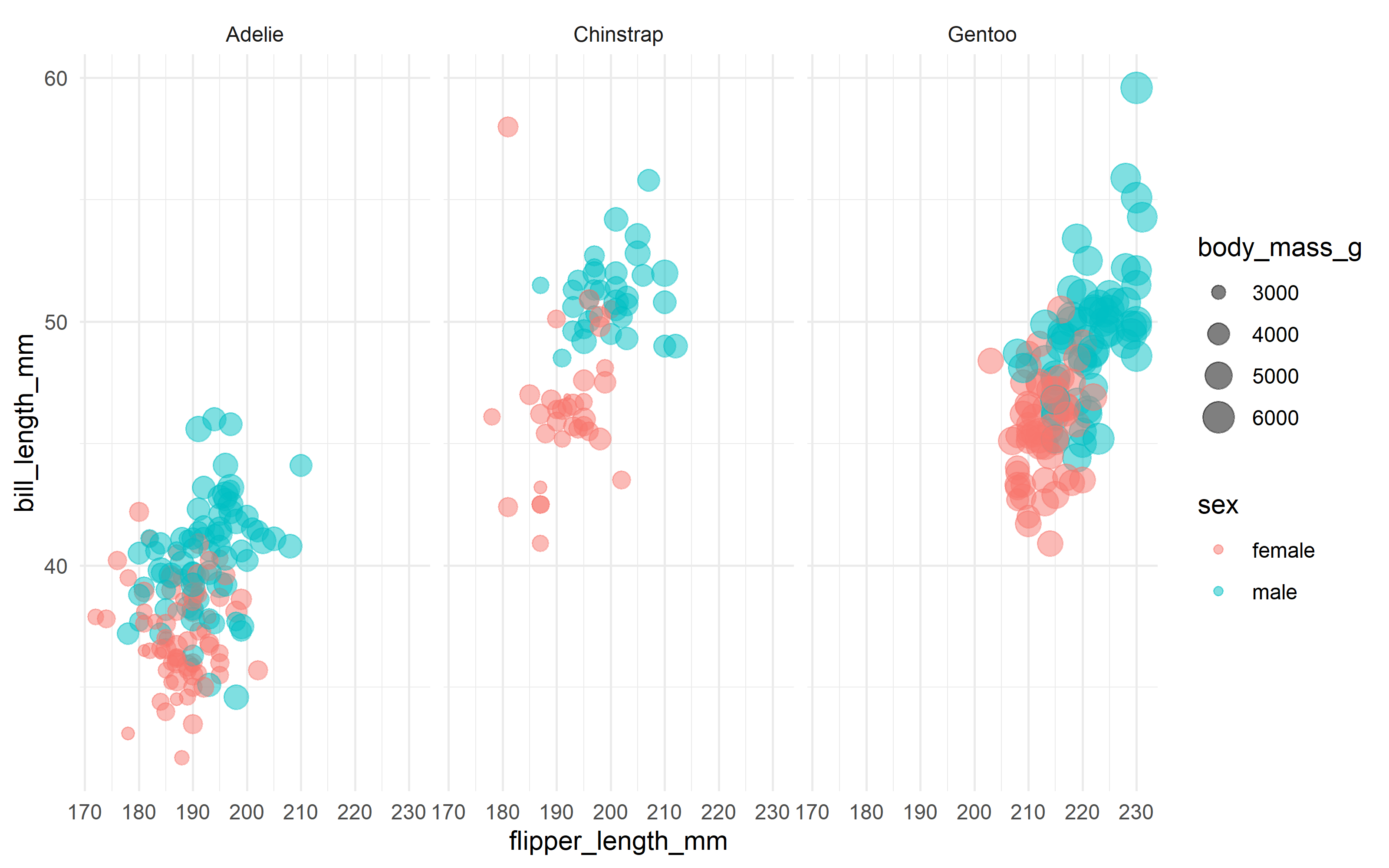
It is easier to classify and predict species than the sex of the species as the different physical characteristics are what makes a species different from each other. But sex somewhat harder to predict.
From the above graph it looks like female penguins have smaller with differet bills. Now let’s build a model but first remove year and island from the model.
Logistic Regression Model Specification (classification)
Computational engine: glm
# random forest modelrf_spec <-rand_forest() %>%set_mode("classification") %>%set_engine("ranger")rf_spec
Random Forest Model Specification (classification)
Computational engine: ranger
Next let’s start putting together a tidymodels workflow(), a helper object to help manage modeling pipelines with pieces that fit together like Lego blocks. Notice that there is no model yet: Model: None.
It is finally time for us to return to the testing set. Notice that we have not used the testing set yet during this whole analysis; the testing set is precious and can only be used to estimate performance on new data. Let’s fit one more time to the training data and evaluate on the testing data using the function last_fit().
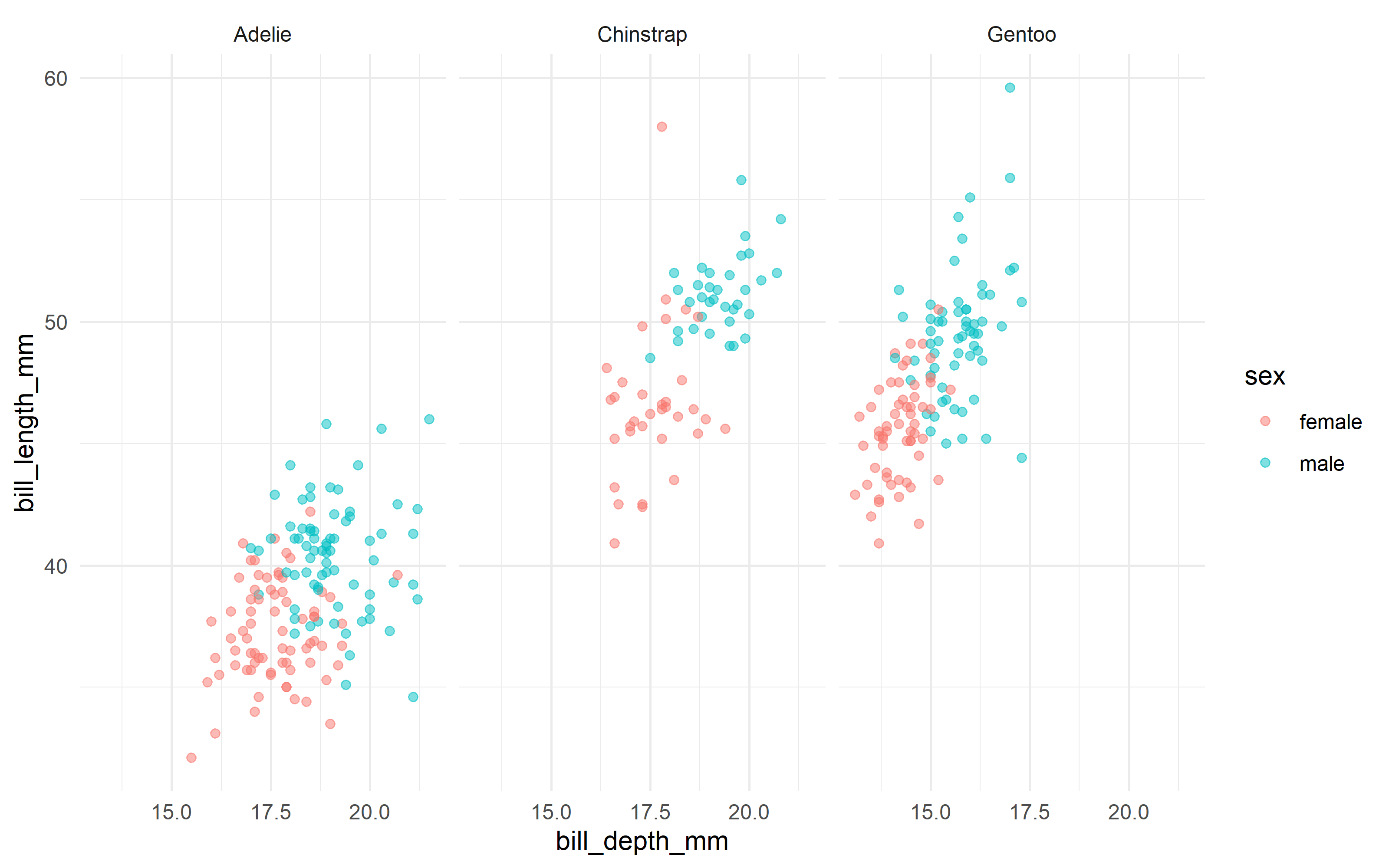
The largest odds ratio is for bill depth, with the second largest for bill length. An increase of 1 mm in bill depth corresponds to almost 4x higher odds of being male. The characteristics of a penguin’s bill must be associated with their sex.
We don’t have strong evidence that flipper length is different between male and female penguins, controlling for the other measures; maybe we should explore that by changing that first plot!